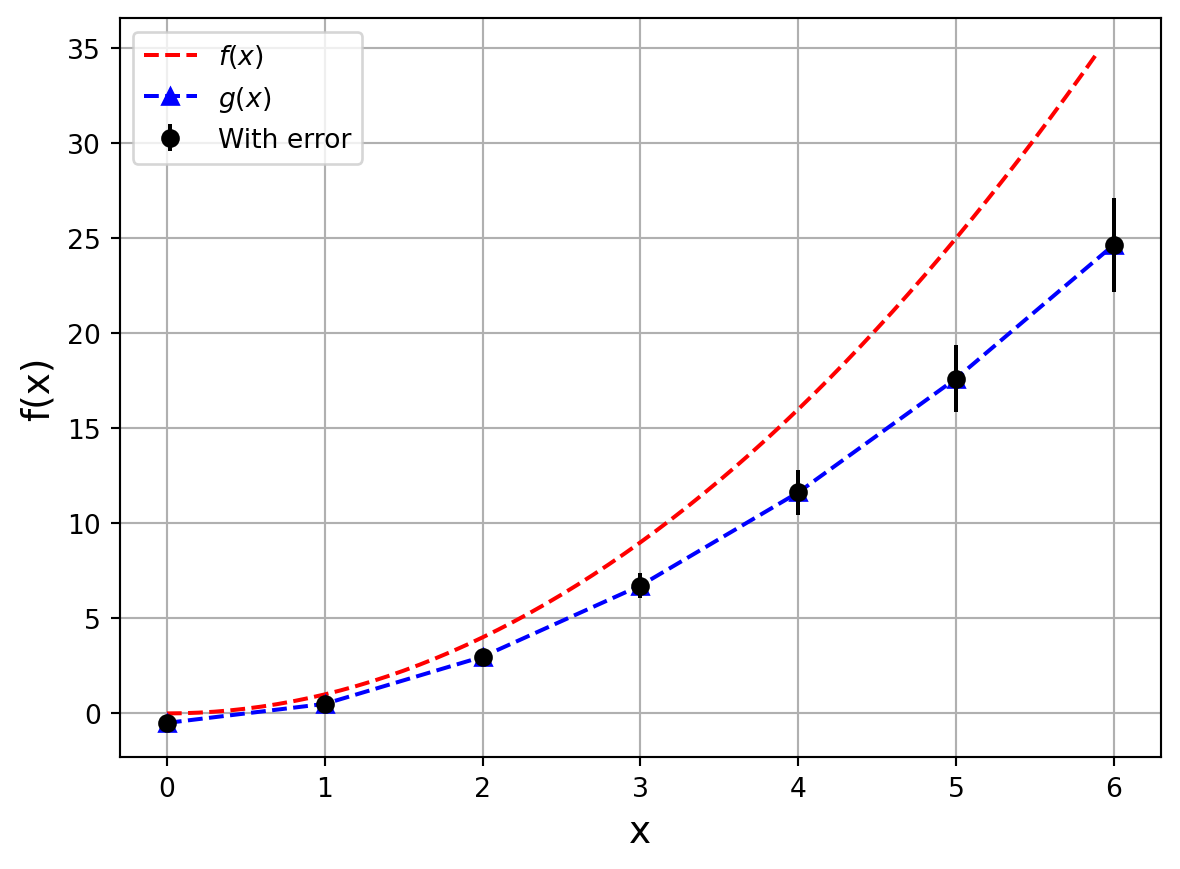
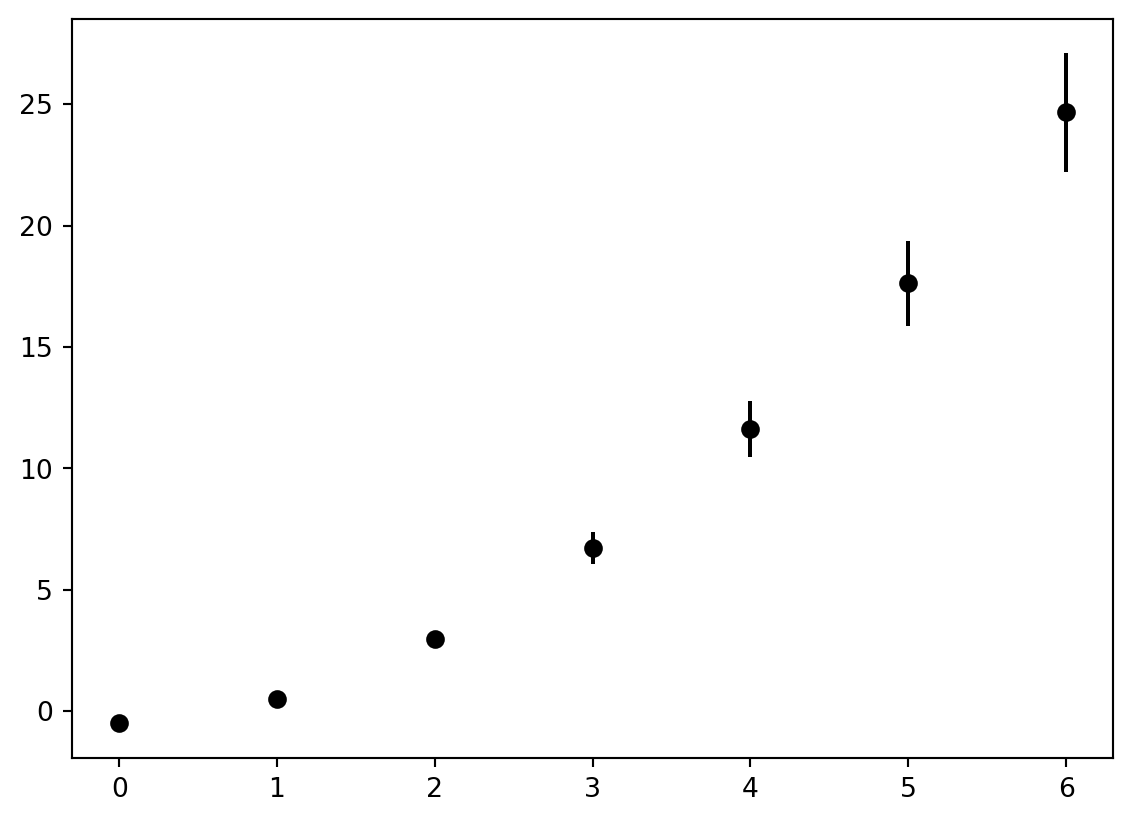
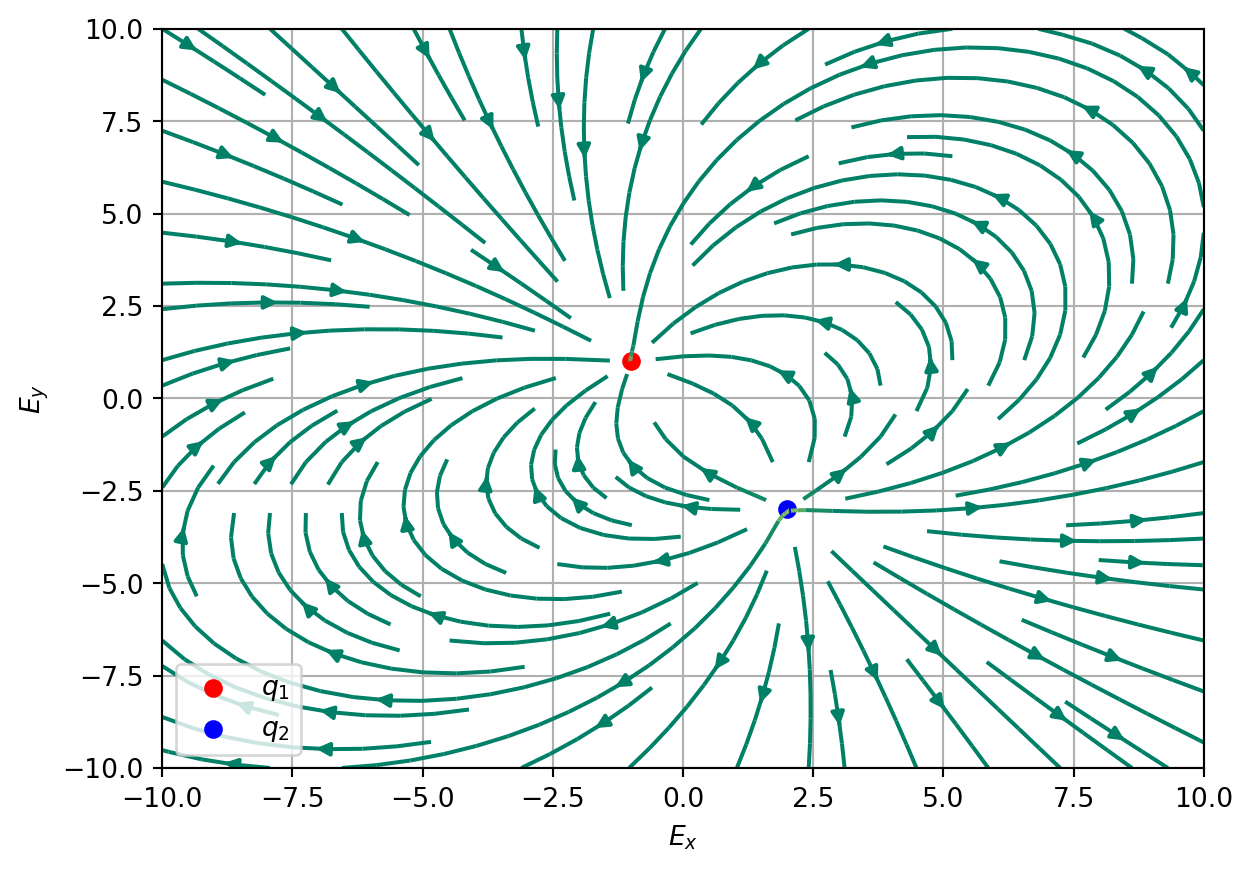
[0.18219827008714864,
0.7481491802575803,
0.22290229423424848,
0.17046943920542806,
0.494938813541671,
0.39211185990701375,
0.11098659150486885,
0.6187634856729576,
0.7373422487936492,
0.009612861424962376,
0.25844789732889156,
0.17238479472504203,
0.001572691780614067,
0.18356525541883628,
0.15809173888038922,
0.3788773933325553,
0.03169090423118541,
0.32523136841508427,
0.9517328610480859,
0.5005772858986157,
0.3280504335872162,
0.00674803991851377,
0.015605736816390067,
0.05244392455238989,
0.09257225596250036,
0.5003306967416153,
0.5133883760233291,
0.1280286610450579,
0.07426735979549648,
0.2098134489563944,
0.11368921369463522,
0.06109693651768494,
0.10728516997932482,
0.3105650955605598,
0.1660253704882784,
0.08335007614814877,
0.17609348939556482,
0.031316430348806525,
0.17388853565002765,
0.18042605609757936,
0.36471641857535414,
0.03365255292567646,
0.12525452786818178,
0.07622152833576921,
0.21903233107522552,
0.5249844548961476,
0.034212454358207765,
0.30224144849688916,
0.5830063509354293,
0.509599507979244,
0.5261002668974939,
0.23597365808464313,
0.22707359140282102,
0.31285965730741117,
0.03043362195474699,
0.010459082357887133,
0.539789286084372,
0.08838540676674124,
0.6996425940001086,
0.048373748785535645,
0.11194309161031614,
0.40528691959915464,
0.5853329590862385,
0.028986236561587334,
0.10002595149974144,
0.16142449586434657,
0.5376026461074219,
0.5392736701351482,
0.5232622011770306,
0.16149024385344346,
0.49007795505115404,
0.24201999463076793,
0.3943429187513581,
0.018782025459347998,
0.15228435767602594,
0.8956643775416108,
0.19172156116359512,
0.01691572839222918,
0.03584752424499268,
0.12727587971953244,
0.18688408752410834,
0.18921886197666835,
0.20980928408672933,
0.11586690252673561,
0.022759557570475392,
0.00588228062157452,
0.03816834340433043,
0.06991151181340476,
0.537820784354661,
0.23971298260023433,
0.19119580355923577,
0.0863346375085274,
0.3585491504573777,
0.015885972524031726,
0.38807069779536835,
0.4219789736983442,
0.10319590635280007,
0.18539876076907832,
0.30920580181047774,
0.5947328533326081]